고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
[ 제 네이버 블로그 글을 티스토리로 이전한 글입니다. 해당 글은 제 네이버 블로그에 2018.06.09에 작성되었었습니다 ]
Kdnuggets에서 inbalanced 데이터에 대한 글을 보다가, 정리해두면 좋을 것 같아서 글을 작성한다.
실제 데이터를 다루다보면, imbalanced 데이터를 다룰 때가 많다.
특히나 사람을 대상으로 인지적인 실험을 할 때, class 데이터 비율을 조절하기가 난감할 때가 종종있다.
나의 경우 이러한 데이터를 다룰 때는 data augmentation을 통하여 data가 부족한 class의 데이터 수를 보충해주거나, confusion matrix를 확인해보면서 모델의 성능을 확인하는 편이다.
* Imbalanced 데이터: 전체 데이터 중, 특정 class 데이터가 대다수를 차지하고 있는 경우를 말함.
(예) 2 class 데이터 1000개가 있다. 이 때, class 1은 980개(98%)를 차지하고, class 2는 20개(2%)를 차지한다.
kdnuggets에서 추천하는 방법들은 아래와 같다.
(1) 적절한 evaluation metrics 들을 사용해라.
- accuracy만 볼 것이 아니라, {precision, recall, F1 score}등을 고려하여 모델의 결과를 확인할 것을 권고.
(2) 학습 데이터 resampling
1) under-sampling: 데이터 수가 많은 class에서 데이터 수가 적은 class의 수를 고려하여, 적절한 양을 선택해서 가져옴.
(단점: 데이터 수가 많은 class의 특성을 일부 놓칠 수 있다.)
2) over-sampling: 데이터 수가 적은 class의 데이터를 늘임. data augmentation 방법 적용 가능. (kdnuggets에서는 SMOTE나 MSMOTE 알고리즘을 추천)
(3) K-fold cross-validation의 사용
- k-fold cross-validation: 전체 학습 데이터를 k개의 그룹으로 나눈 후, 한 그룹을 validation set, 나머지 그룹을 train set으로 설정. validation을 k번 행할 때까지, 학습이 수행됨. (아래 그림 참고, 아래의 경우는 6-fold cross-validation이다)
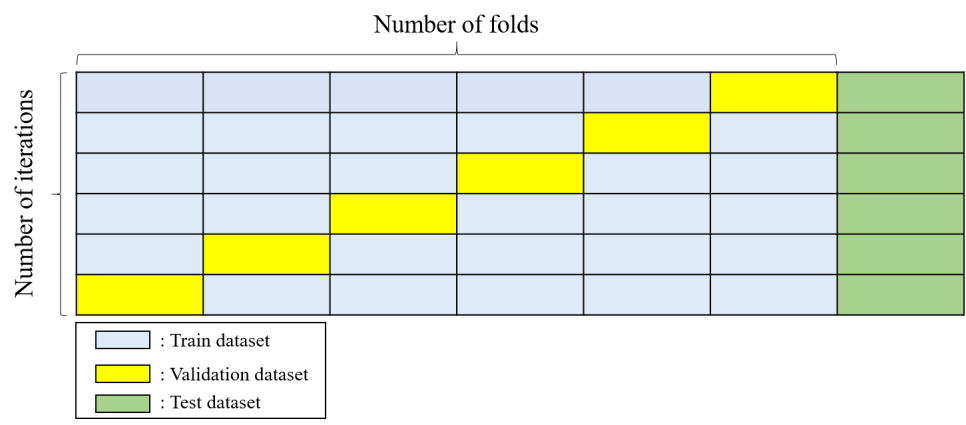
(4) resample 데이터 조합을 여러개로 하여 합침.
- 데이터 수가 많은 class를 데이터 수가 적은 class의 데이터 개수를 고려하여 n개 그룹으로 나눔.
이 후, n개의 분류기를 n개 그룹과 데이터 수가 적은 class의 데이터로 각각 학습 시킨 후, ensemble 함. (kdnuggets 포스트에서는 이 방법이 가장 쉬운 접근이라고 함.)
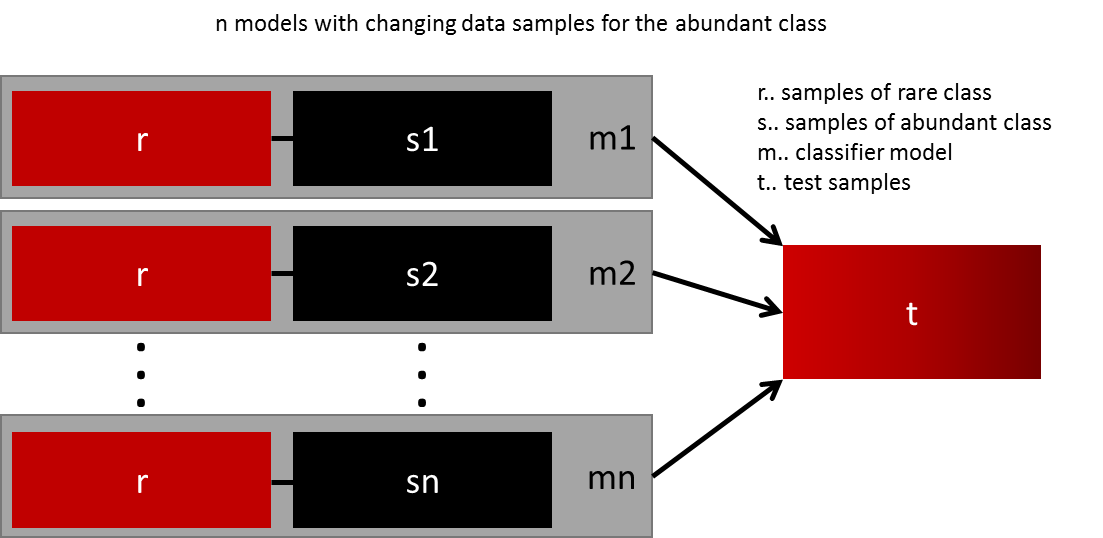
(5) (4)의 방식과 유사하지만, 데이터 수가 많은 class의 데이터 비율을 바꿔가면서 여러 모델을 만든 후 합침.
- 데이터가 많은 class의 데이터 수 비율을 다양하게 하여, 각각의 모델을 데이터 수가 적은 class의 데이터와 함께 학습 시킨 후, ensemble 함.

(6) 데이터 수가 많은 class의 데이터를 클러스터링 한 후, 각 클러스터 별로 학습 후 ensemble 함.
(7) 모델을 수정함
- 쉬운 방법 중 하나로는, 데이터 수가 적은 class에 대한 분류가 잘 못되었을 때, cost를 크게 주는 방법이 있음.
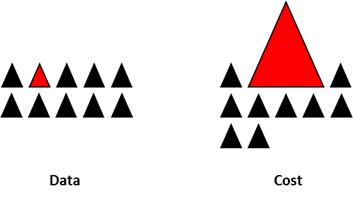
Imbalanced 데이터 다루는 방식은 매우 다양하므로, 자신의 데이터 특성을 보고 적절한 것을 선택해서 반복적으로 테스트 해봐야한다.
(절대적인 것은 없다)
참고)
https://www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html
7 Techniques to Handle Imbalanced Data - KDnuggets
This blog post introduces seven techniques that are commonly applied in domains like intrusion detection or real-time bidding, because the datasets are often extremely imbalanced.
www.kdnuggets.com
Three techniques to improve machine learning model performance with imbalanced datasets - KDnuggets
The primary objective of this project was to handle data imbalance issue. In the following subsections, I describe three techniques I used to overcome the data imbalance problem.
www.kdnuggets.com
728x90
반응형
'Machine learning' 카테고리의 다른 글
| Brain-inspired machine learning... Computational machine learning (0) | 2021.08.06 |
|---|---|
| Data augmentation에 관한 글 (0) | 2021.08.04 |
| 학습 데이터와 테스트 데이터의 차이가 있을 때 (gap between train dataset and test dataset) (0) | 2021.08.02 |
| Batch normalization 관련 (0) | 2021.08.02 |
| Stroop task (스트루프 태스크) (0) | 2021.08.02 |





댓글 영역