고정 헤더 영역
상세 컨텐츠
본문 제목
[논문 읽기] Meta-RangeSeg: LiDAR Sequence Semantic Segmentation Using Multiple Feature Aggregation
본문
728x90
반응형
최근에 LiDAR 관련 논문들을 많이 보는 편입니다. LiDAR 센서는 강력한 성능을 보여주기는 하지만, 카메라에 비해 가격이 많이 비싼편입니다. 테슬라를 제외하고는 대부분의 각 차 메이커의 고급 차종에는 LiDAR가 매립되어 있습니다. 저의 경우 앞으로 LiDAR센서를 건드릴 가능성이 높아서, 관련 논문들을 확인하고 있는 중입니다.
어떤 논문을 보면 유용할까 arxiv에서 관련 논문을 찾던 중에, 오늘 작성하는 논문이 눈에 들어왔습니다. Abstract만 읽어보고 선택을 했는데, 3D LiDAR 데이터 세트를 효과적으로 표현하고 처리하는 방법에 대한 논문이라 선택했습니다.
저자: Song Wang, Jianke Zhu, Ruixiang Zhang
Abstract
기존의 대부분 LiDAR 데이터 처리 방법들은 3D point cloud를 2D 구형 좌표 이미지로 변환하여 2D 영상처리에 특화된 딥러닝 네트워크들을 활용해서 처리하였습니다. 이러한 방법은 기존은 영상처리에서 활용된 딥러닝 네트워크를 빠르게 적용할 수 있다는 장점이 있지만, LiDAR데이터의 정보를 모두 활용하지 못한다는 단점이 있습니다. 또한, 시간 정보를 고려하는데 한계가 있었습니다. 이러한 단점들을 해결하기 위해서, 이 논문에서는 새로운 형태의 range residual 영상 표현방법을 제시하여 semantic segmentation을 적용하였습니다. 이를 위해, Meta-Kernel이 적용되었으며, 이 kernel을 통해서 2D range 영상 좌표 입력과 Cartesian 좌표계의 출력간의 불일치정도를 줄였습니다. Multi-scale 특징점들을 얻기위해서 efficient U-Net 구조가 활용되었습니다. Feature Aggregation Module(FAM)을 통하여 meta feature들과 multi-scale feature들을 붙였습니다. 실험은 Semantic KITTI를 활용하여 좋은 결과를 얻을수 있었습니다. 관련 code는 https://github.com/songw-zju/Meta-RangeSeg에서 볼수 있습니다.
Semantic segmentation
- 의미론적인 segmentation (각 pixel이 속한 category기반으로 분류)
이전의 LiDAR기반 semantic segmentation approaches
- Point-based 방법
- LiDAR센서의 출력으로부터 바로 feature 추출하는 방법
- 단점: point convolution의 계산량이 매우 큼 - Voxel-based 방법
- raw point cloud 데이터를 일정한 형태의 grid 표현으로 변환하여 기존의 convolution layer 적용
- 단점: 원 데이터의 정보를 모두 보존하지 못함 - Hybrid 방법
- point-based 방법과 voxel-based 방법을 융합
- 더 좋은 결과물을 얻지만, 계산량이 매우 커짐
Scene analysis
- 대부분의 이전 방법들은 LiDAR semantic segmentation에서의 single frmae을 활용하였다고함
=> 시간 정보 소실
Contribution of this paper
- LiDAR 데이터의 시간-공간적인 정보를 잘 담아낼수 있는 Meta-RangeSeg 방법 제안
- LiDAR 데이터로부터 feature를 추출하는 Meta-Kernel feature extraction 방법 제안
- 여러 scale로부터의 meta feature를 붙여처리하는 Feature Aggregation Module (FAM) 제안
- 제안 방법을 공용 SemanticKITTY benchmark상에 실험하여 성능 검증
Meta-RangeSeg for LiDAR Semantic Segmentation
아래에 이 paper의 주요 framework를 캡쳐해놓았다. 아래 그림을 살펴보면, 일단 LiDAR데이터는 Spherical projection을 통해서 2차원 구형 좌표계로 사영되는 것으로 보인다. 현재 frame으로부터 {range, (x, y, z), intensity, mask}가 추출되는 것으로 보이고, 현재 frame과 이전 frame간의 차이로부터 residual images들이 추가로 추출되는 것으로 보인다. 이 입력들에 대하여 Meta-Kernel이 적용되어 meta feature가 추출되며, U-Net으로부터 multi-scale feature가 추출된다. 마지막으로, aggregated feature를 post-processing함으로써 최종 label을 가진다.
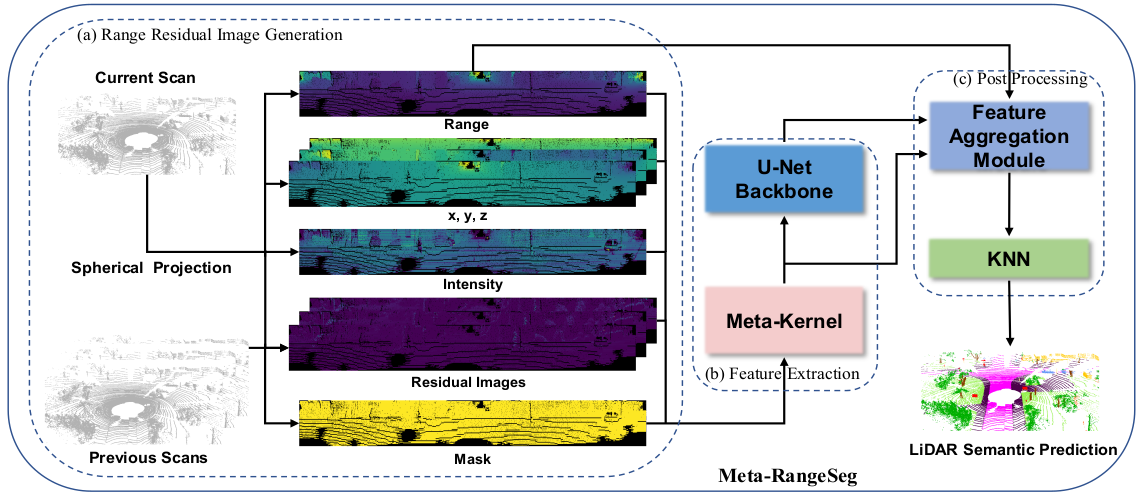
네트워크 학습시에는, weighted cross-entropy loss와 Lovasz loss, Boundary loss를 weight 합으로 사용하는데, Lovasz loss와 Boundary loss에 대해서는 조금 더 찾아봐야되겠다. 논문에 나온 내용을 참고하자면...
- Lovasz loss는 semantic segmentation에 주로 사용되며 intersection-over-union(IoU) score를 최대화하는 loss라고 한다. 이 부분에 대하여 설명하면서, 수학적 증명이 일부 제시되었다.
- Boundary loss는 다른 object들 간의 경계선을 강화하기 위해 적용된 loss라고 한다. 해당 loss에 대해서도 수식적으로 표현을 논문에 해놓았다.
Range residual image부분에서 어떻게 LiDAR point cloud 데이터를 2D 구형 좌표계로 변환했는지 설명하고 있다. 또한, residual image의 의의와 추출방법에 대하여 설명을 해두었는데, 실제 코드를 돌려보면서 확인해봐야지 체감이 될 것 같다 .
Feature extraction
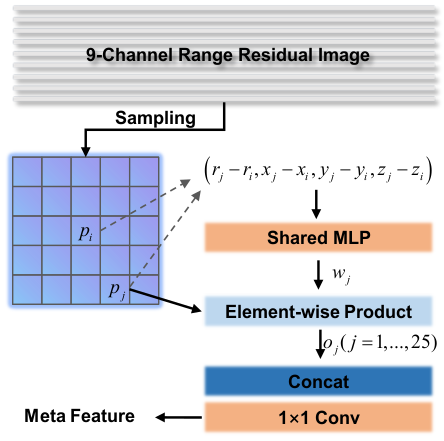
이 부분은 Meta-Kernel block과 U-Net backbone으로 이루어져 있습니다. 실험 중에, 기존의 convolution operation들이 range residual 영상에 적합하지 않은 것을 확인했다고 합니다. 이 부분을 개선하기 위해서, Meta-Kernel을 활용해 meta feature를 추출했다고 합니다.
Post processing (feature aggregation module)
추출한 feature들을 feature aggreagtion module(FAM)에서 모은다. Feature들을 정리할때는 ResNet을 참고해서 skip connection도 넣어서 convolution filter를 거쳤다.

현재 github에 demo video까지 올라온 상태인데, 코드가 마저 올라오면 테스트해봐야겠다.
728x90
반응형
'Machine learning' 카테고리의 다른 글
| NVIDIA container toolkit 설치 (0) | 2022.03.24 |
|---|---|
| [nvidia driver 에러] error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: initialization error: nvml error: driver not loaded: unknown. (0) | 2022.03.23 |
| Quantum Neural Networks (양자 신경망, 양자 머신러닝) (0) | 2021.08.27 |
| Bayesian inference 관련 링크들 (0) | 2021.08.18 |
| Weight initialization (웨이트 초기화) (0) | 2021.08.13 |





댓글 영역