고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
[ 제 네이버 블로그 글을 티스토리로 이전한 글입니다. 해당 글은 제 네이버 블로그에 2018.06.30에 작성되었었습니다 ]
Kdnuggets에 올라와 있는 글들 중, weight initialization에 관한 글이 있어서 정리하였습니다.
저의 경우 weight initialization을 할 때, 보통 Xavier initialization을 많이 사용하는 편입니다. 경험적으로는, random 초기화 방법보다는 학습속도가 빠른 것으로 느껴집니다.
해당 글에서는 fully connected neural network을 기준으로 설명을 하고 있습니다.
Neural Network의 학습은 크게 4단계로 이루어집니다.
1) network의 parameter들(weight, bias) 초기화 .
2) Forward propagation: 데이터를 network에 입력하여, network의 출력단(prediction)까지의 처리과정.
3) Loss function 계산: loss function은 actual label과 prediction 값을 입력 변수로 한다. loss function 계산을 통해, actual label값과 prediction값 간의 차이를 알 수 있다. Network 학습의 목적은 이 loss function을 줄이는데 있다.
4) Backward propagation: network의 error치(prediction 값과 target 값 간의 차이)를 보정하기 위해, 출력단에서 입력단으로 역 방향으로 error치를 고려한 parameter update.
5) 2)~4)과정을 loss function이 최소가 되거나 학습 종료 조건이 될 때까지 반복해준다.
이 글은 weight 초기화에 집중하여 글을 기술하였습니다.
Weight 초기화의 방법들은 다음과 같습니다.
(1) 0으로 모든 weight 초기화
- 이 경우, network은 선형 모델과 동일하게 됩니다.
- 0으로 weight를 초기화하게되면, 모든 weight가 loss function에 대하여 같은 미분 값을 가지게 됩니다. (즉, 모든 weight의 값이 매 순간 같습니다.)
- Bias의 경우 0으로 모두 초기화해도 상관없다고 합니다.
(2) weight random 초기화
- weight random 초기화의 경우, 2가지 issue를 가져올 수 있다고 합니다.
1) Vanishing gradients
- activation function을 tanh나 sigmoid 함수같은 것을 사용할 경우, layer가 깊어지면질수록 입력층에 가까운 layer의 피드백 성분이(back propagation값) 점점 0에 가까워지는 현상입니다. (출력 layer에서의 error를 보정하기 위한 연산이 입력 layer에 가까워지면 질수록 영향력이 줄어듬)
- ReLU activation 함수를 사용하면 이 현상을 막을 수 있습니다.
2) Exploding gradients
- gradient가 매우 커지는 현상입니다. (vanishing gradient와는 반대 상황)
- 이 경우, loss 함수가 NaN(Not a number)값을 가질수도 있으며, 부정확한 연산을 하기도 합니다.
글쓴이는 위의 현상들을 막기 위해 다음의 3가지 방안을 소개합니다.
(1) ReLU나 leaky ReLU activation 함수의 사용
- softmax함수나 tanh함수의 경우 미분을 많이할수록 0으로 수렴할 가능성이 많습니다. 반면, ReLU함수 계열은 미분을 아무리 많이해도 원래 값의 성분을 선형적으로 다음 layer로 전달가능합니다.
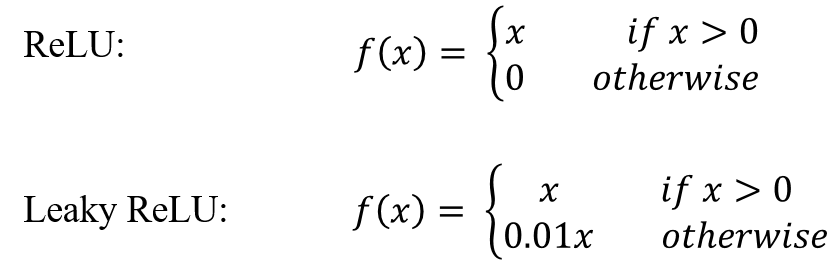
(2) Heuristic approach
- Xavier initialization이나 He initialization등을 고려할 수 있다.
(3) Gradient clipping
- exploding gradient 문제를 다루기 위한 방법.
- gradient 값에 대한 threshold값을 설정.
만약, gradient가 threshold값을 넘어갈 경우 해당 gradient값을 다른 gradient값(정규화 한 값등으로)으로 대체.
예) W' = W*threshold/l2_norm(W)
참고)
https://www.kdnuggets.com/2018/06/deep-learning-best-practices-weight-initialization.html
Deep Learning Best Practices – Weight Initialization - KDnuggets
In this blog I am going to talk about the issues related to initialization of weight matrices and ways to mitigate them. Before that, let’s just cover some basics and notations that we will be using going forward.
www.kdnuggets.com
728x90
반응형
'Machine learning' 카테고리의 다른 글
| Quantum Neural Networks (양자 신경망, 양자 머신러닝) (0) | 2021.08.27 |
|---|---|
| Bayesian inference 관련 링크들 (0) | 2021.08.18 |
| (KDnuggets) 데이터 분석에 주로 사용되는 5가지 clustering 알고리즘들 (0) | 2021.08.12 |
| (kdnuggets) 데이터 이해하기 (0) | 2021.08.11 |
| non-Gaussian distribution (0) | 2021.08.09 |





댓글 영역