고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
[ 제 네이버 블로그 글을 티스토리로 이전한 글입니다. 해당 글은 제 네이버 블로그에 2018.07.04에 작성되었었습니다 ]
KDnuggets에서 clustering에 관한 글이 올라왔다.
정리해두면 유용할 것 같아서, 정리해둔다.
clustering은 종종 사용하는 편이다. 주로, data의 특성을 확인하기 위해 사용한다.
나의 경우에는 사람의 감정을 분류하는 일을 종종하는데, 관련 논문들 중 몇몇은 감정 score의 적절한 threshold value를 찾기위해 clustering 알고리즘을 적용하기도 했다.
아래 문장이 중요한 것 같다. 원문 그대로 복사해둔다.
'In Data Science, we can use clustering analysis to gain some valuable insights from our data by seeing what groups the data points fall into when we apply a clustering algorithm.'
참고 글에서는 5가지 주로 사용되는 clustering 알고리즘을 소개하였다.
1. K-Means clustering
- K-Means clustering은 다른 알고리즘들에 비해, 직관적으로 쉽게 이해된다.
- K-Means clustering은... Data를 K개로 clustering하는 것으로써...
random하게 k개의 random center position을 설정한 후, data sample들과 center position들간의 거리 계산을 통하여 가까운 center position으로 clustering 하는 것이다.
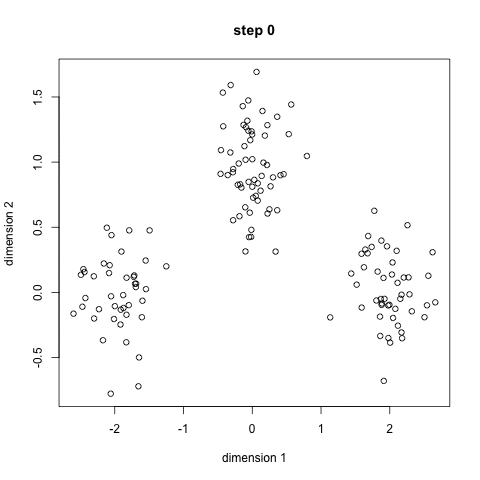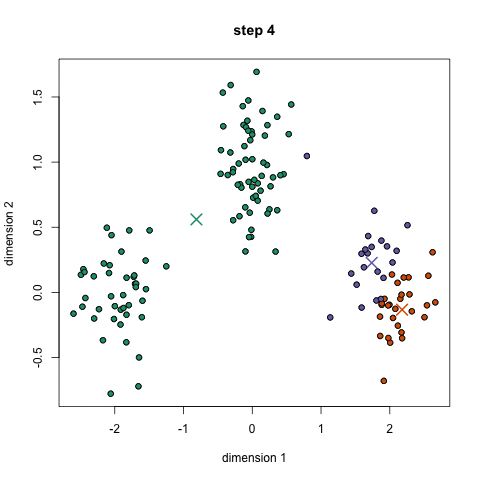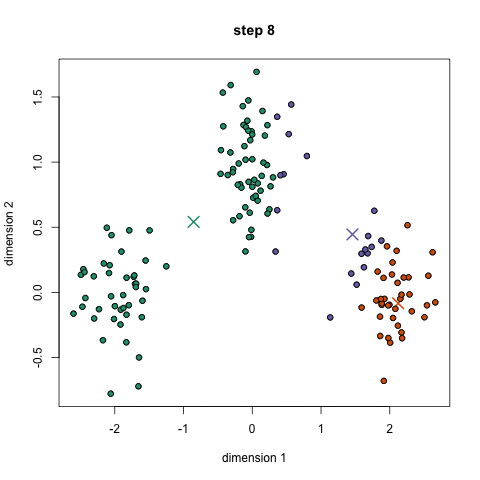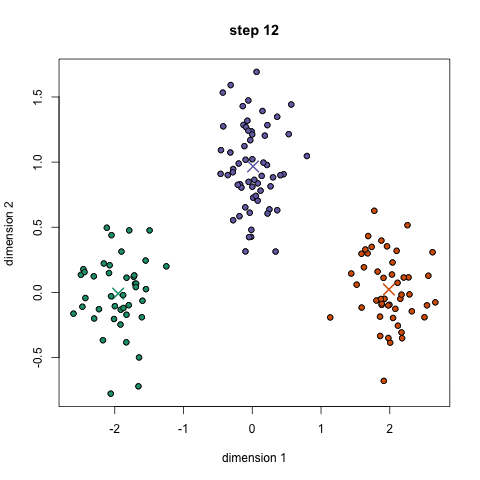
알고리즘
(step 1) K parameter에 대한 사용자의 설정이 필요하다. (이 부분이 disadvantage...)
K parameter 설정 후, random하게 K개의 random position이 설정된다. (적절한 center position의 설정도 중요하다. 초기 center position는 clustering 결과에 영향을 미친다.)
(step 2) 각 data sample들은 K개의 center position에 대하여 거리 계산을 한다.
이 때, 가장 거리가 가까운 center로 data sample은 clustering된다.
(step 3) K개의 center position을 각 cluster에 속한 data sample들의 평균 값으로 update한다.
(step 4) K개의 center position이 사용자가 미리 설정한 임계치 이하로 떨어질 때까지, step2~step3을 반복한다.
| 이점: 계산 속도가 빠르다. 구현이 쉽다. 단점: K parameter의 선택에 따라 clustering 결과가 다르다. center position 초기값에 따라 다른 결과를 얻을 수 있다. (결과가 일관적이지 않다.) |
2. Mean-Shift clustering
- Mean-Shift clustering 알고리즘은 sliding-window 기반이라고 한다. Window가 data의 dense한 곳을 search한다. 이 때, window 내의 data sample들의 평균(mean) 위치가 window의 center position으로 update된다.
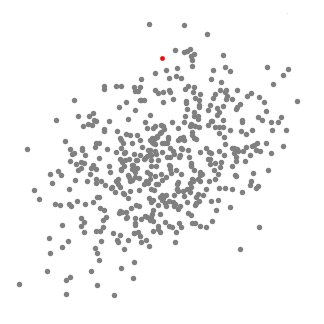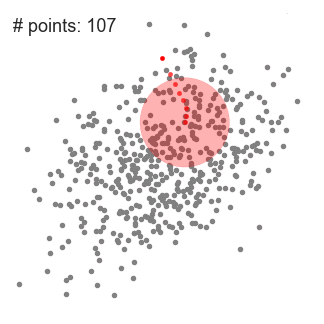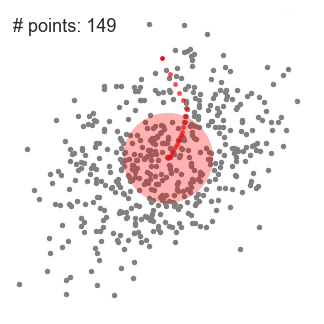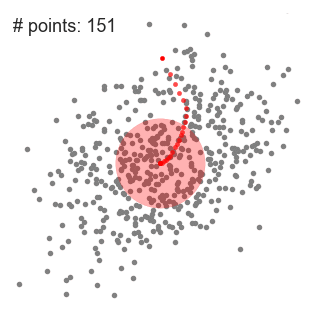
알고리즘 (2차원 공간에서...)
(step 1) center position이 C고 반지름이 r인 window들을 data 공간에 설정한다.
(step 2) 매 iteration마다 sliding window들은 data density가 더 높은쪽으로 center position을 이동하며 움직인다. (여기서 density는 window내의 data sample의 개수이다.)
(step 3) Window들이 dense한 영역에 머물러서 converge할 때까지 계속 shifting한다.

| 이점: K-means clustering 알고리즘과는 달리 cluster의 갯수를 미리 설정할 필요가 없다. 단점: window의 반지름 크기 r의 설정에 따라서 clustering 결과가 달라질 수 있다. |
3. Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
- 이 알고리즘을 사용해본적은 아직 없다. 참고 글에서는 이 알고리즘은 mean-shift 알고리즘과 유사하지만, mean-shift 알고리즘보다 좋다고 한다.
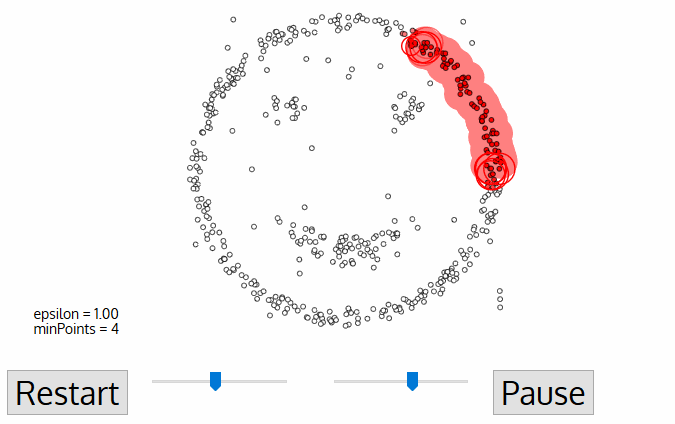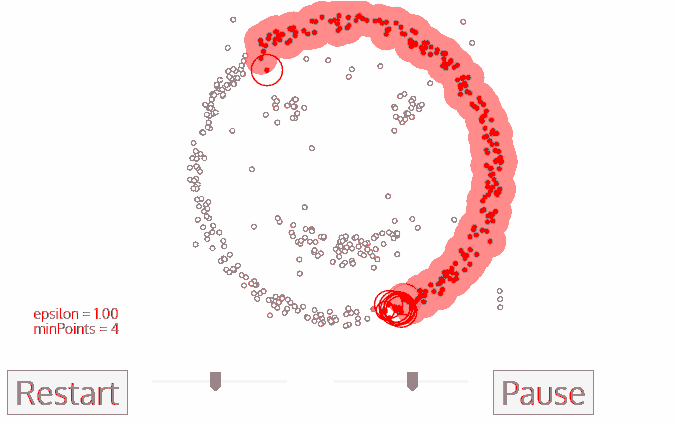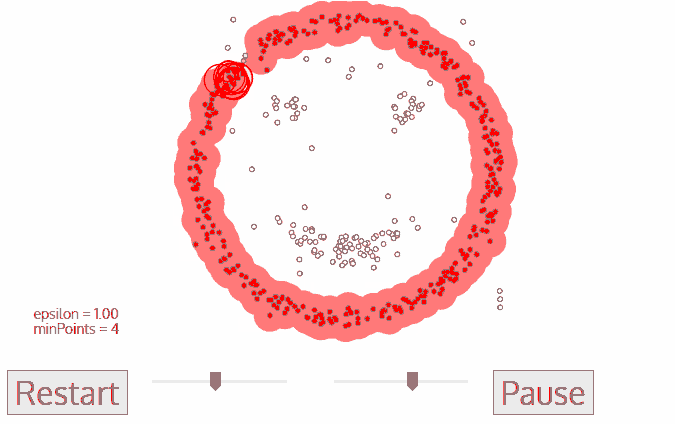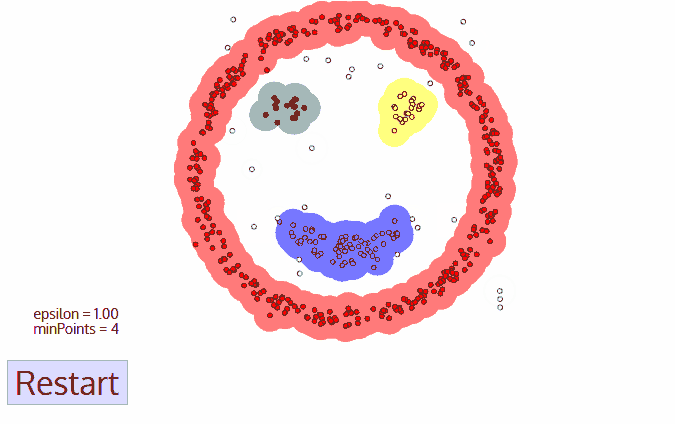
알고리즘 (2차원 공간에서...)
(step 1) 선택된 적이 없는 임의의 data sample 위치에서 거리 epsilon 내에 위치한 주변 data sample들을 확인한다.
(step 2) 만약, epsilon 거리 안에 충분한 수의 data sample들(사용자가 설정)이 있다면, clustering 과정을 수행한다. 즉, 처음에 선택한 data sample이 새로운 cluster의 첫번째 지점이 된다.
반면에, epsilon 거리 안에 충분한 수의 data sample들이 없을 경우, 선택한 data sample은 noise로 label해둔다.
(step 3) 처음에 선택한 data sample이 epsilon 거리 내에 충분한 data sample들이 있어 cluster를 형성할 경우, epsilon 거리 내의 data sample들도 같은 cluster로 표기해준다.
(step 4) step 2와 step 3을 cluster가 결정될 때까지 반복해준다. (epsilon 거리 내의 모든 data sample들을 확인하고 label해야한다.
(step 5) 하나의 cluster에 대하여 확인이 된 이후에, 새로운 un-visited 지점의 data sample을 임의로 선택하여 step 2~step 4의 과정들을 행해준다. 모든 sample들이 확인될 때까지 반복한다.
| 이점: cluster 개수를 미리 정할 필요가 없다. outlier는 noise로 구분하여 처리한다. (잡음에 강건) 단점: data 밀도가 다양할 경우, 다른 clustering 알고리즘들보다 clustering 결과가 좋지 않음. (epsilon 값과 충분한 sample이 있다고 판단하는 threshold값이 data 밀도에 따라 달라져야한다.) |
4. Expectation-Maximization(EM) clustering using Gaussian Mixture models (GMM)
- GMM을 이용한 EM clustering은 K-means에 비해 조금 더 flexible하다고 한다. EM은 GMM의 2개의 파라미터(mean, standard deviation)를 추정하는데 사용된다.
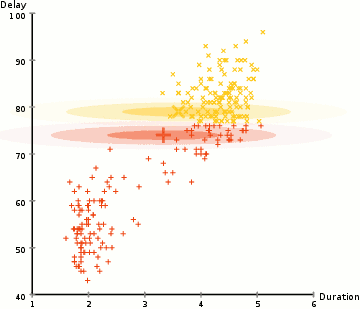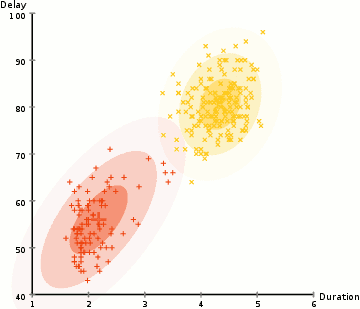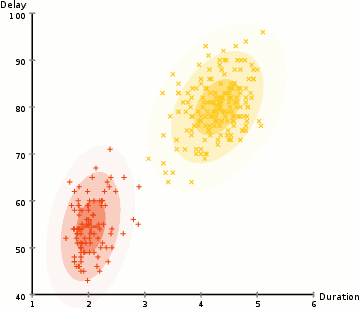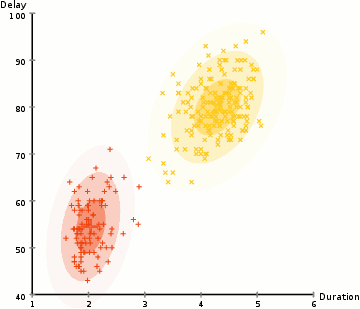
알고리즘 (2차원 공간에서...)
(step 1) cluster의 수를 임의로 설정하고, 각 cluster의 Gaussian 분포 parameter들을 random하게 초기화한다.
(step 2) 각 cluster에 대하여 Gaussian 분포를 설정한 후, 각 data sample이 각 cluster에 속할 확률을 계산한다. Gaussian 함수의 center 위치에 가까우면 가까울수록 해당 cluster에 속할 확률이 높아진다.
(step 3) Gaussian 분포의 parameter들을 업데이트한다. 업데이트는 data sample이 해당 Gaussian분포내에 위치한 position 정보를 바탕으로 weight를 적용하여 수행된다. Weight는 해당 data sample이 특정 cluster에 속할 확률이다.
(step 4) Gaussian 분포의 parameter들이 converge할 때까지, step 2와 step 3을 반복해서 수행해준다.
| 이점: - standard deviation 파라미터의 사용으로 인해, K-Means 알고리즘에 비하여 훨씬 flexible하다. (K-Means는 원형으로 데이터 clustering을 수행하는데에 반해, GMM기반의 clustering은 standard deviation 항을 이용하여, 여러형태로 모델을 표현가능하다.) - 확률 기반 방법이므로, mixed membership 형태로 표현가능하다. (class 1에 대해서는 x% 속할 확률을 가지고 있고, class 2에 대해서는 y% 속할 확률을 가지고 있다.) |
5. Agglomerative Hierarchical clustering
- Hierarchical clustering 알고리즘은 botton-up형식과 top-down형식의 2가지 범주로 나눌수 있다. Bottom-up알고리즘은 각 data sample들을 하나의 single cluster로 다루고 모든 cluster들이 하나의 cluster로 합쳐질때까지 cluster들을 연속적으로 합친다.
- Hierarchical cluster는 나무로써 표현된다. (나무의 뿌리 부분은 모든 sample들을 모은 unique한 cluster이며, 잎 부분은 하나의 data sample들로써 표현된다.)
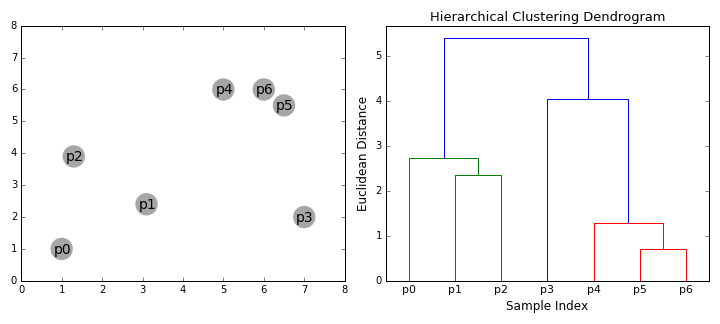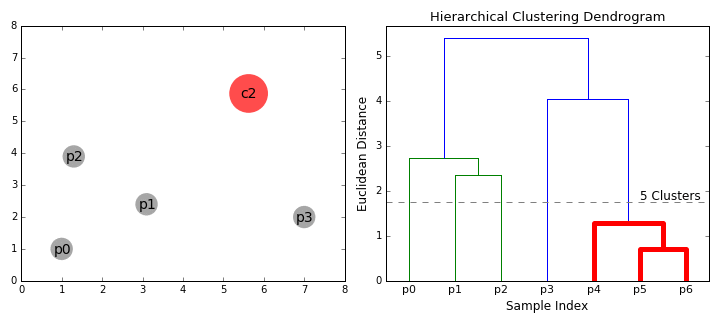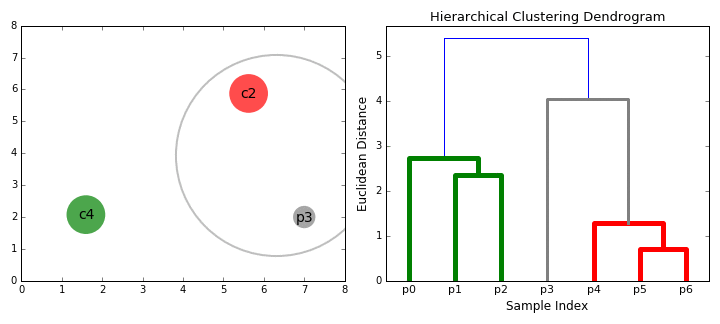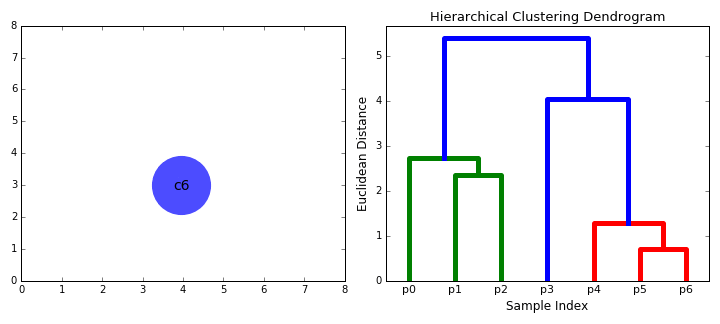
| 이점: cluster의 수를 미리 정할 필요가 없다. tree형태를 만든 이후에 cluster의 수를 지정할 수도 있다. 거리 계산 방식에 대하여 강건하다. (어떠한 거리 계산 방식을 사용하더라도, 결과가 비슷하게 나온다. ) 단점: 계산량이 많다. |
참고)
https://www.kdnuggets.com/2018/06/5-clustering-algorithms-data-scientists-need-know.html
The 5 Clustering Algorithms Data Scientists Need to Know - KDnuggets
Today, we’re going to look at 5 popular clustering algorithms that data scientists need to know and their pros and cons!
www.kdnuggets.com
728x90
반응형
'Machine learning' 카테고리의 다른 글
| Bayesian inference 관련 링크들 (0) | 2021.08.18 |
|---|---|
| Weight initialization (웨이트 초기화) (0) | 2021.08.13 |
| (kdnuggets) 데이터 이해하기 (0) | 2021.08.11 |
| non-Gaussian distribution (0) | 2021.08.09 |
| Brain-inspired machine learning... Computational machine learning (0) | 2021.08.06 |





댓글 영역